Desktop application that allows you to open PDF chess books.
Mainly programmed during Covid-19

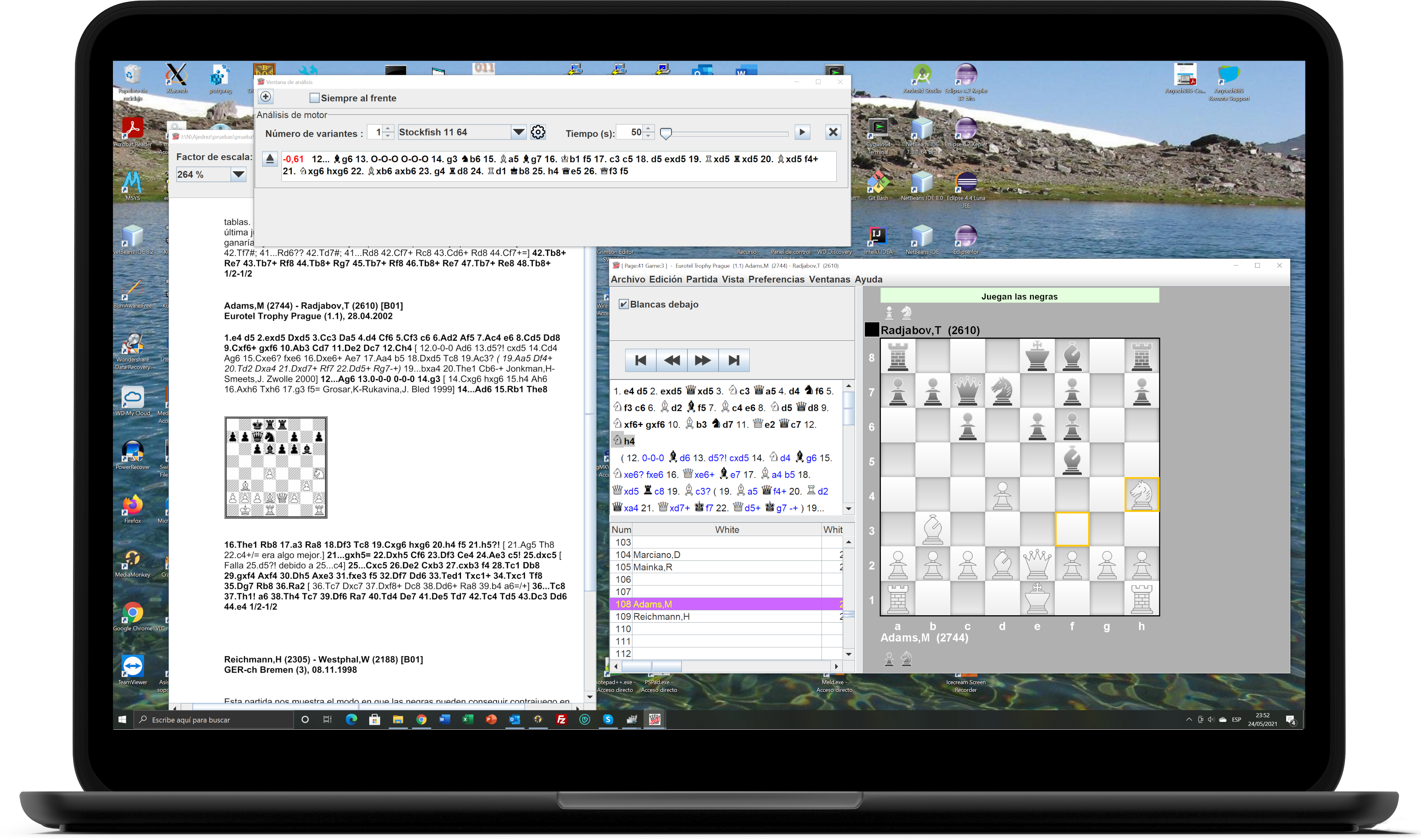
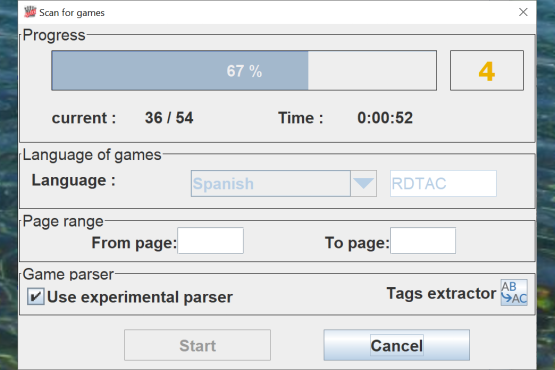
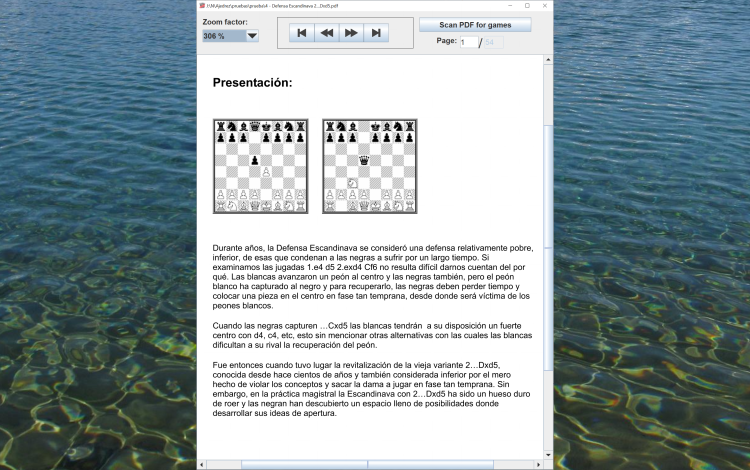
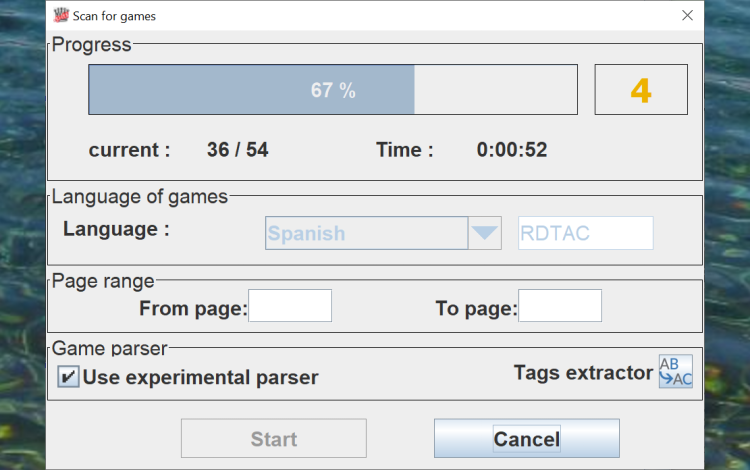
You can extract the games from the PDFs

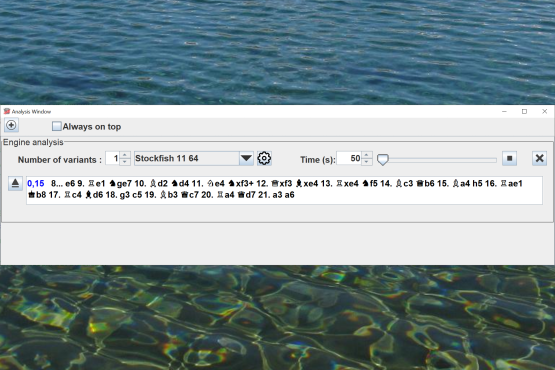
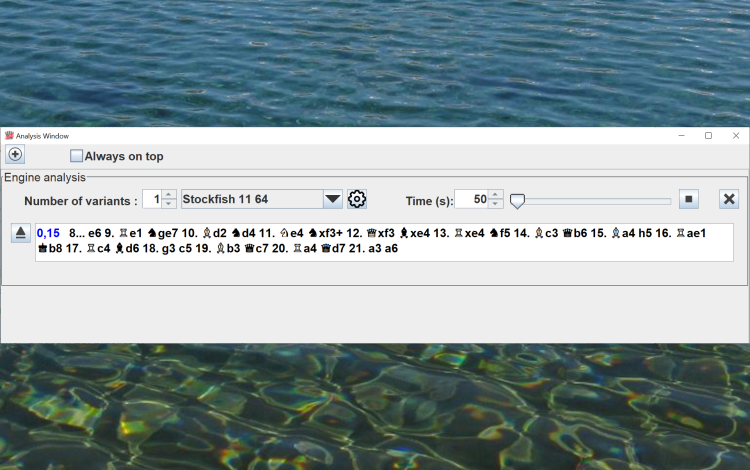
Position analysis connecting to
UCI engines

Programmed in Java swing
Multiplatform chess application
Programmed in Java swing

User interface in Spanish, Catalan, and English

Zoom in or zoom out of the global view of the application
You can pull out the games from the PDF
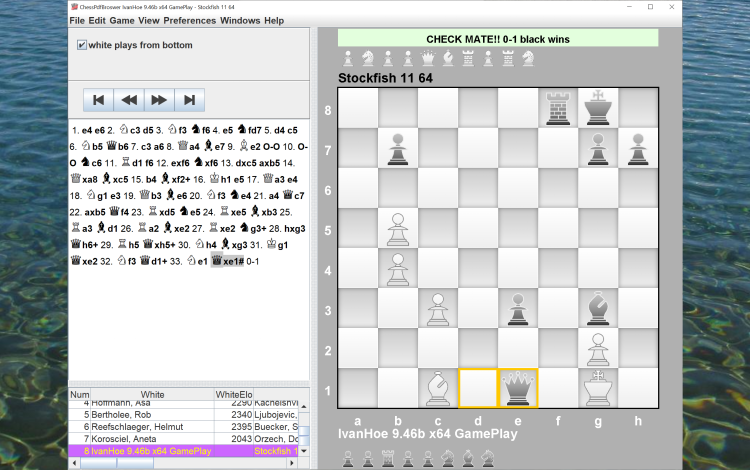
Analysis with UCI engines

You can save the games in PGN format
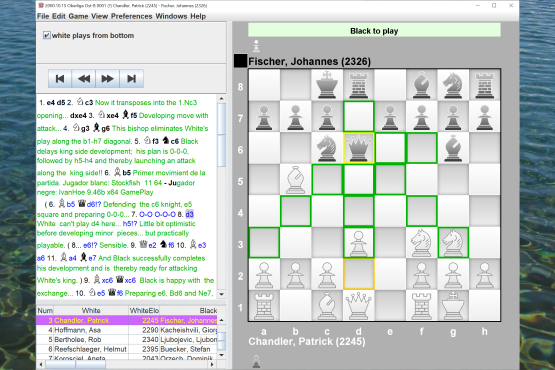
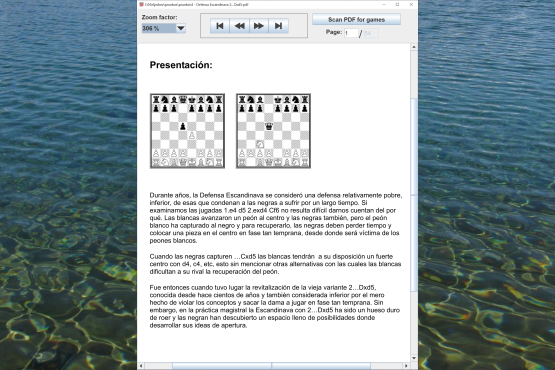
Open and browse through your PDF chess books.
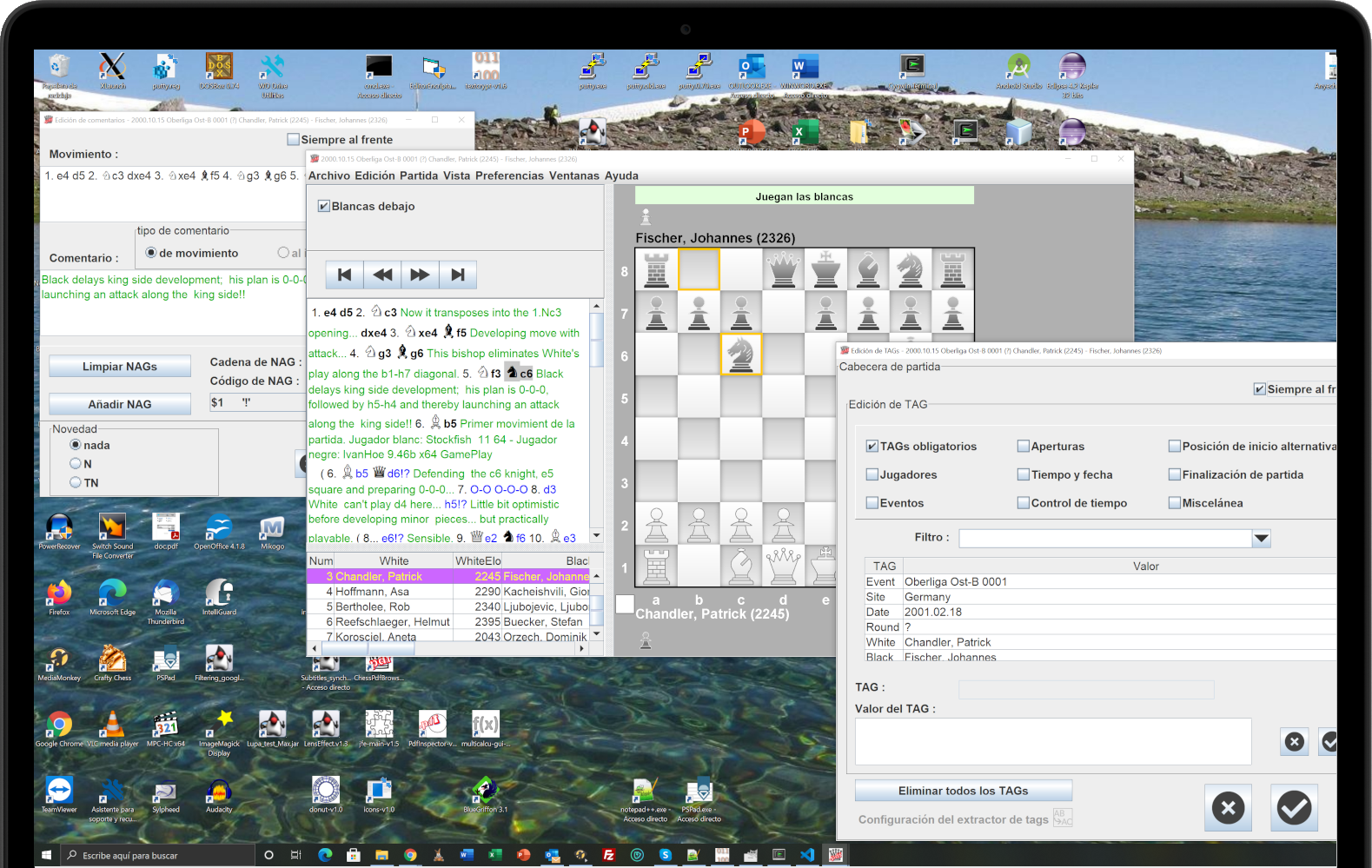
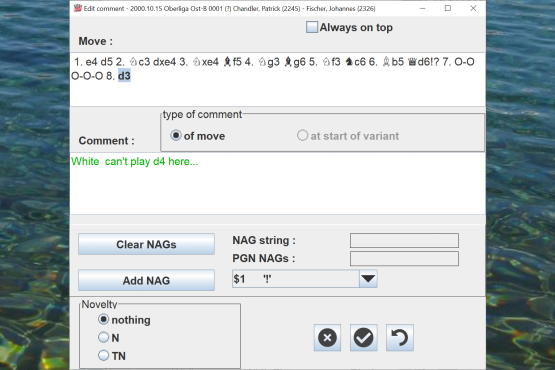
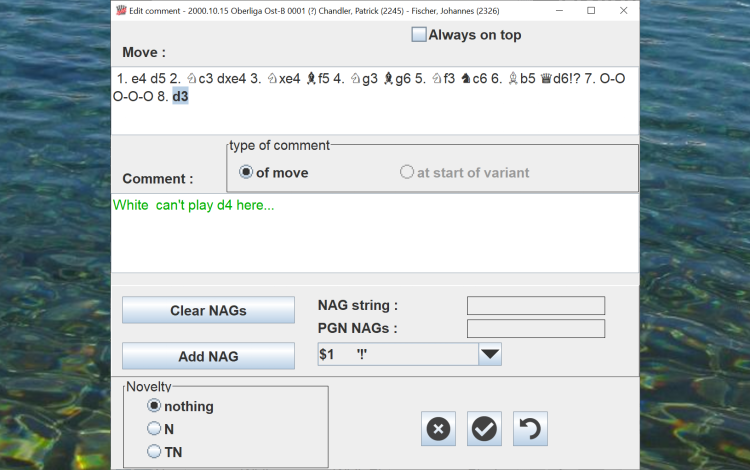
Edit the comments of the games, or add new comments.
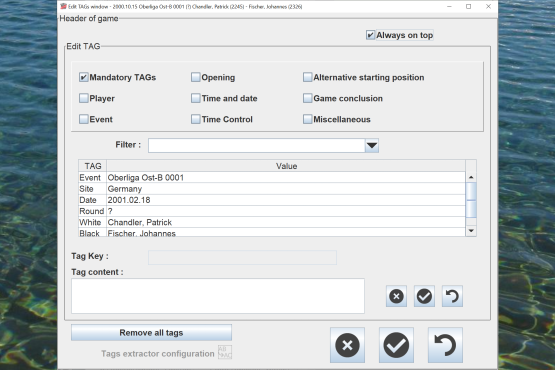
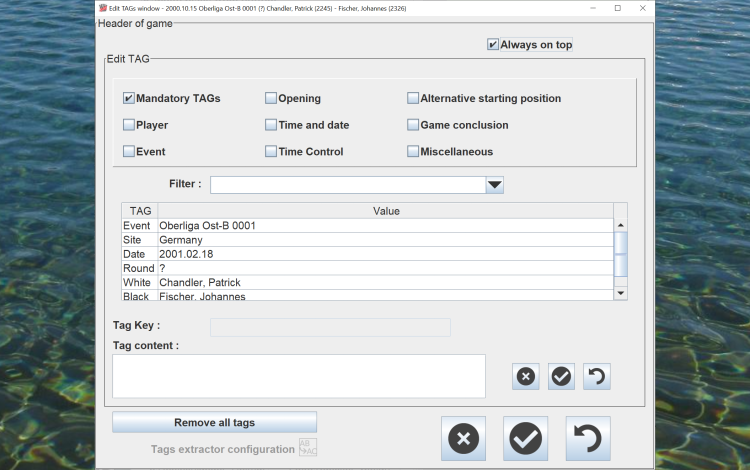
Edit the game tags (player names, ELOs, site, event, ...).
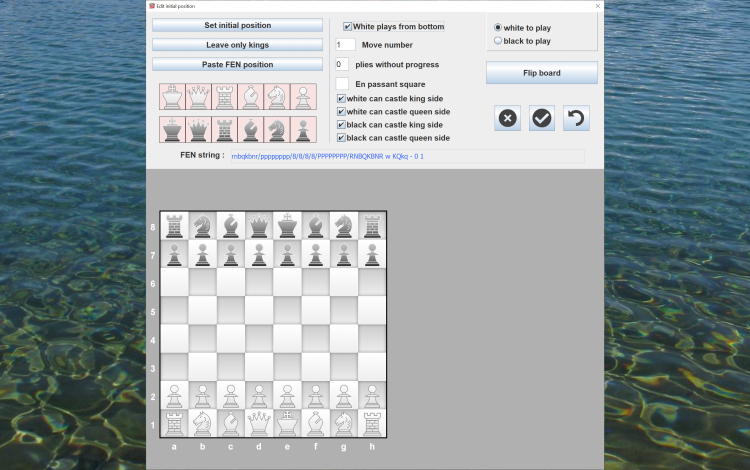
Edit the starting position of the games that need it.
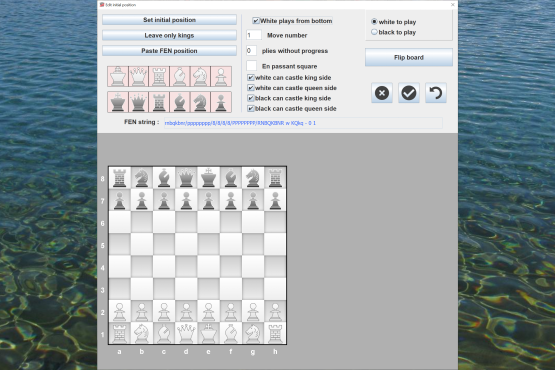
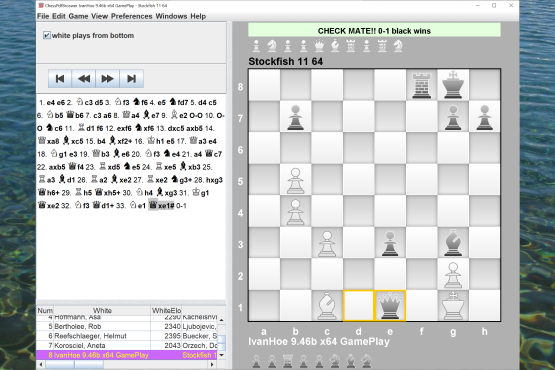
Play timed games against an engine or a friend, or have two engines play against each other.
Read more
You can train the piece detector to extract games in figurine algebraic notation
Read MoreImpressiones from a developmental point of view.

Programming this application has given me a lot of satisfaction, seeing it grow day by day, and how I grew along with it ... an interesting experience.
Samples of screens from the application
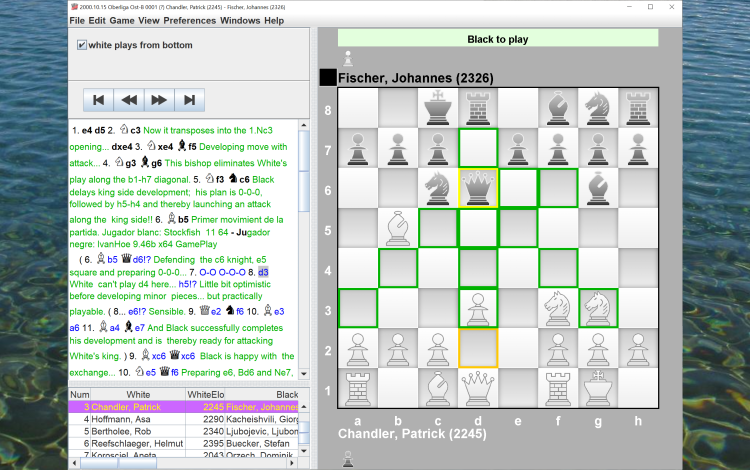
Some numbers about the application.
The application is completely free and open source.
Example video
A single developer works behind the scenes.

The application can be downloaded from several open source websites.
Frequently Asked Questions
Whether it's to say hi, talk about the application
or report bugs.